Training Procedures¶
ml4t-models does not hide all estimators behind one generic trainer because the model
families do not train the same way.
Some estimators are closed form. Some emit neural checkpoints every few epochs. The stochastic discount factor family has phased adversarial training. Portfolio learners optimize a turnover-aware objective directly. The library keeps those differences explicit and makes checkpoint reporting part of the public contract.

Why Checkpoints Are First-Class¶
In the book and case studies, neural estimators are often evaluated at several training horizons rather than only at the last epoch. The library therefore treats checkpoint emission as configuration, not as hidden trainer behavior.
The practical rule is:
- estimators emit the checkpoints you configured
- downstream code decides how to score or compare them
- prediction defaults stay explicit through
default_checkpoint
This keeps model semantics and evaluation semantics separate.
Closed-Form And Alternating Estimators¶
PCAModel, RPPCAModel, and IPCAModel do not expose an epoch grid in the same sense as
neural models.
PCAModelandRPPCAModelare eigendecomposition-based estimatorsIPCAModeluses an alternating least-squares loop with convergence controls- all three report structural output at
epoch = 0
That convention matters in cross-family comparisons: epoch = 0 means "no neural training
timeline applies here," not "the model was left untrained."
Checkpointed Neural Estimators¶
CAEModel, SAEModel, and the portfolio learners expose explicit checkpoint controls.
Typical knobs are:
n_epochsormax_iterscheckpoint_interval/checkpoint_everycheckpoint_epochs/checkpoint_stepsdefault_checkpoint
Use interval checkpoints when training horizons are short and dense comparison is cheap.
That is a good default for CAEModel, SAEModel, and lighter portfolio learners.
Conditional Autoencoder Training¶
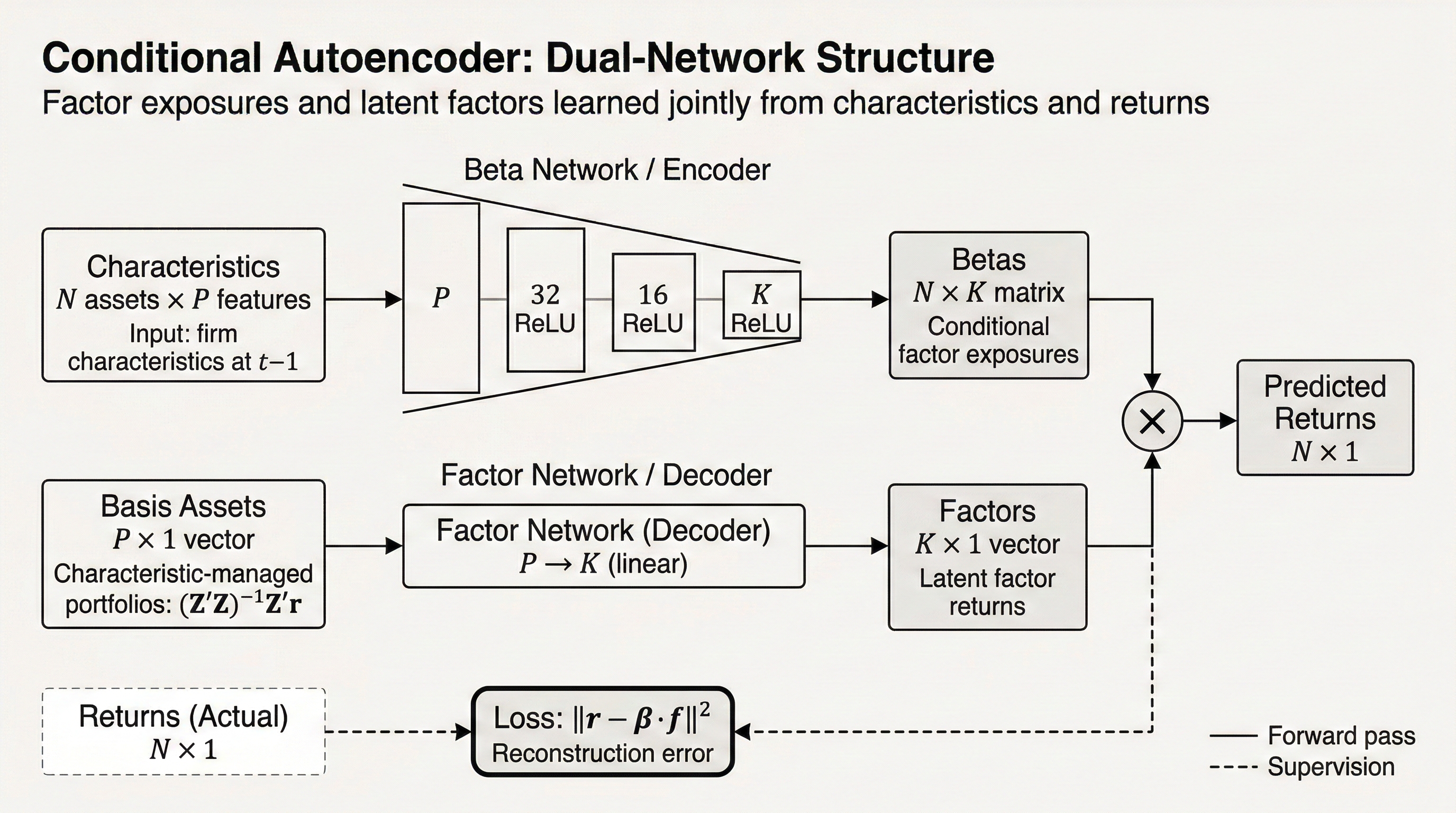
CAEModel follows the conditional autoencoder structure of
Gu, Kelly, and Xiu (2021):
- a beta network maps characteristics to conditional exposures
- managed portfolios summarize the realized cross-section
- a factor side turns those managed portfolios into latent factor returns
- reconstruction loss ties the two together
Checkpointing is especially useful here because the structural state extracted at epoch 10 can lead to a different factor-premium forecast than the state extracted at epoch 50.
Phase-Aware Stochastic Discount Factor Training¶
StochasticDiscountFactorModel has a different protocol entirely. Following
Chen, Pelger, and Zhu (2021),
training is split into three phases:
- unconditional SDF warm-up
- moment-network fitting
- conditional SDF refinement
This is why the config has n_epochs_unc, n_epochs_moment, and n_epochs_cond instead of
one generic n_epochs.
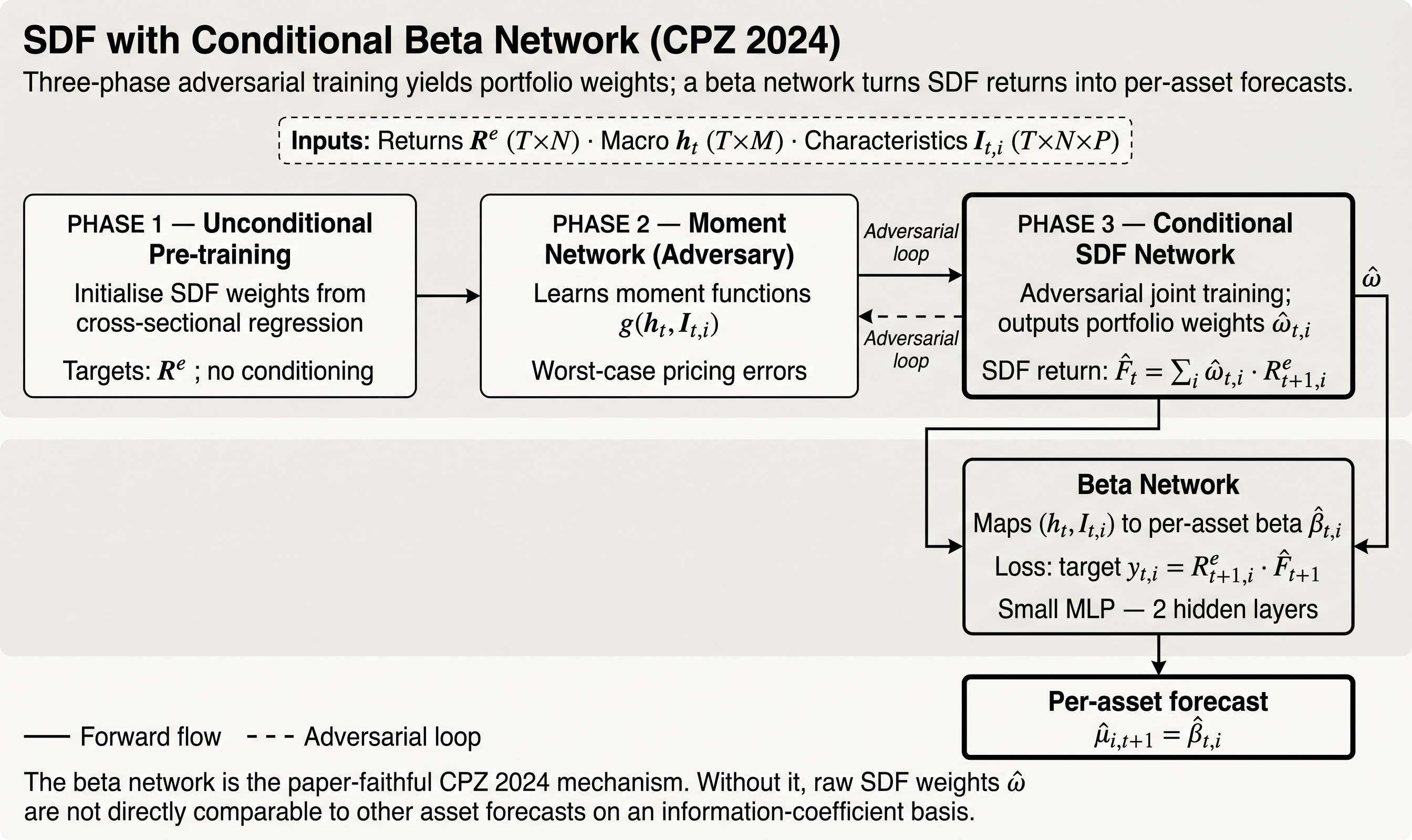
The optional beta-network head has its own smaller checkpoint grid. That separation matters: the structural SDF fit is expensive and should usually be evaluated at sparse named milestones, while the beta head can often be trained on a shorter schedule.
For long phased models, prefer:
- explicit
checkpoint_epochs - explicit
beta_checkpoint_epochs
over dense interval checkpointing.
Portfolio-Learning Training¶
Portfolio learners optimize allocation objectives directly rather than stopping at a return forecast.
Shared portfolio controls include:
checkpoint_everyorcheckpoint_stepseval_everyearly_stopping_patienceturnover_penaltygamma_cost
Those controls are part of the public model config because they change the learned policy, not just the reporting surface.
Reporting Rules¶
The library keeps three reporting rules consistent across families:
- Emitted checkpoints are configuration, not hidden trainer state.
default_checkpointcontrols whatpredict()orextract()returns by default.- Selection logic belongs outside the estimator.
That last rule is important. If you want to compare checkpoints by cross-sectional IC,
Sharpe, or any other metric, do it in ml4t-diagnostic or in your case-study orchestration,
not inside the model class.
Practical Defaults¶
Use these defaults unless there is a clear reason not to:
PCA,RP-PCA,IPCA: no checkpoint sweep; reportepoch = 0CAE,SAE: moderate training horizon with interval or explicit checkpoint listsStochasticDiscountFactorModel: sparse structural checkpoints and a smaller beta-head grid- portfolio learners: checkpoint every few optimization steps, with early stopping and cost-aware validation